之前做过两年的运维,用过很多命令,深切体会到某些linux命令熟练掌握后对效率提升有多大。举个简单的例子,在做了研发后经常会有跑一些数据,对于结果数据的处理,我们的产品同学一般都习惯于用excel做统计,把数据复制到excel里,然后数据分列,排序………… 最后得出某些简单的结论,我只需要cat, sort, uniq, awk, grep 这几个命令挥手间完成相同的操作。
这里我总结下我工作这几年用过的一些命令,当然,这里就不提那些vim cd ls mv cp 这种简单的命令了,如果你都不会这些命令的话,建议你先学习下。这里命令很多,我只简单列出几个我常用的参数。其实很多命令我也用的不是特别多,这篇文章我也只是希望能让大家知道有这样一个工具,但具体用如果想继续深入了解的话建议查看下手册,部分比较命令我也列出了有些参考资料。
服务器运行状态相关命令
ps
查看系统进程线程,我一般都是用这个命令查看进程pid的,然后用pid做更深入的排查。
基本用法
ps -aux 查看所有进程
ps -T -p ${pid} 查看某个进程的线程
参考资料
pstree
查看系统进程树,他可以把各个进程之间的关系用树形结构标识出来。
基本用法
pstree
top
查看系统进程线程运行情况,包裹资源的使用情况,系统负载等。我的用法是看下服务器上负载是否很高,然后看具体是哪个进程,哪个线程占用cpu比较多。
基本用法
top 列出所有线程负载信息
top -H 列出所有线程的负载信息
top -H -p ${pid} 列出某个pid下所有线程的负载信息
free
查看内存及使用情况
基本用法
free
文件操作相关
cat
我都是用这个命令查看配置文件,或者是日志文件,但是有点需要注意,cat命令会把整个文件输出到终端了,如果文件内容非常多,建议使用grep进行过滤,或者直接用less或more命令。
基本用法
cat file.txt
tail
查看某个文件的尾部,或者查看标准出入的最末尾,默认值显示10行,可以用-n参数来指定输出多少行。
基本用法
tail -n 100 file.txt 输出最末尾的100行
tail -f file.txt 随着文件新增,持续输出新增的内容,一般用来看实时日志
head
和tail命令很相似,不过head是输出头部内容,个人感觉head远没有tail命令用的多。
基本用法
head -n 100 file.txt 输出最开始的100行
more
也是用来查看文件,但more命令只加载一屏的内容,可以向下翻动,因为加载的内容少,所以比cat快多了。
基本用法
more file.txt
less
和more很像,但是可以上下翻动,感觉less和more只需要less就可以了,完全可以去掉more啊
基本用法
less file.txt
grep
这个是我非常常用的一个命令了,尤其是在问题排查的时候,需要用grep从大量的数据中筛选出一些我想要的。 grep也支持正则表达式匹配。
基本用法
grep "abc" file 从file中筛选出包含 abc的行。
awk
开头我也说过,这个命令是我最常用的命令之一,比如在文件有多列的时候,我可以用awk输出具体某几列,或者做一些简单的统计 求和,求平均值啊,再或者做一下简单的数据格式化。
基本用法
cat data | awk '{print $1,$3,$5}' 输出第1 3 5列,注意下标是从1开始
cat data | awk '{ sum += $1 } END { print sum }' 对第一列求和
cat data | awk -F'\t' '{print $1,$3}' 把每行数据按tab分列,并输出1 3列
参考资料
sort
对标准内容做排序,
基本用法
cat file|sort 把file里的数据排序,注意是按字典序排的,如果想按数值排,需要能够加-n参数
cat file|sort -k2 -n -r 按第二列 数值 倒序 排序,-k指定第几列,-r是翻转reverse的意思
uniq
对排序好的内容去重,注意它只是把相邻且相同的去重,所以如果想要全局去重,需要先用sort排序。
基本用法
cat file|sort|uniq 把file里的文件排序并去重
cat file|sort|uniq -c 把file里的文件排序并去重,且输出每行出现的次数
sed
parallel
linux大部分命令都是单进程的,这个命令可以让其他命令多进程执行。
参考资料
scp
之前运维大量机器的时候,通常需要批量修改某个配置文件,都是在一台机器上改好,然后用scp脚本分发到其他机器上去的,大大提高效率。
基本用法
scp aaa.txt test@192.168.1.3:/tmp/ 把当前目录下的aaa.txt文件通过192.168.1.3上的test账号放到/tmp目录下
scp test@192.168.1.3:/tmp/aaa.txt . 和上一条相反
磁盘及IO
du
查看目录大小
基本用法
du -h --max-depth=1 输出最深1层的目录,然后文件大小用人类可读的方式,比如1K 234M 2G
df
查看磁盘大小和占用情况
基本用法
df -h 查看各个分区的大小和使用情况
iostat
查看磁盘的io状态
iotop
可以类似于top目录一样,实时显示各个进程的io状态。
find
查找文件,查找条件可以是文件名,文件日期,文件大小,很强大。 我们之前服务器上有个磁盘满就强制删除服务器某个目录下大于1g,且时间大于2天,且文件名是*.log的文件,就是用find加xargs命令做的
基本用法
find /home/test -iname "test.txt 在/home/test/下找文件名为test.txt的文件,也支持通配符
find /home/test -isize +100M 查找/home/test下大于100M的文件
参考资料
locate
定位某个具体文件的位置,locate命令要比find -name快得多,原因是它不搜索具体目录,而是搜索一个数据库/var/lib/mlocate/mlocate.db,这个数据库会通过一个cron定时更新,所以有可能新建的文件会检索不到。
基本用法
locate a.txt 定位a.txt的位置,如果系统中有多个a.txt,会全部显示出来。
tree
可以看到树状目录结构,
基本用法
tree -L 2 只显示两层树状结构
网络
ping
查看网络是否通
基本用法
ping www.baidu.com
nc
netcat,可以用来看远程某个端口是否打开,功能很强大,但是我用到的不多。
基本用法
nc -z xindoo.me 443 检测我服务器上的443端口是否开放(当然是开的)
参考资料
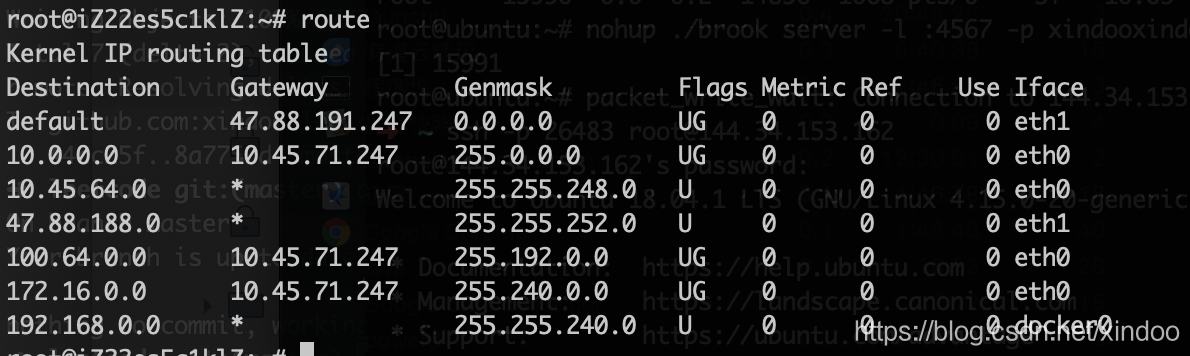
route
查看和操作本机路由表
基本用法
route 列出本地路由表
参考资料
netstat
查看本机的网络状态,可以看到端口占用情况和网络链接情况。
基本用法
netstat -antp
traceroute
查看一个请求到目标服务器所经过的所有路由节点,一般用来排查网络问题。
基本用法
traceroute www.baidu.com
参考资料
iftop
查看实时网络io情况
lsof
查看端口占用
dig
查看域名的信息,之前做运维的时候,经常需要验证某个域名解析改动是否生效,因为一般一个域名会-A到多个ip上,用ping命令只能看到一个ip,这个时候我就会用dig来看域名解析信息了。
基本用法
dig www.baidu.com
参考资料
curl
发起一个http请求,我一般都是用这个命令来验证服务是否能正常访问的,它有获取html源码的功能。
基本用法
curl www.baidu.com
curl -I www.baidu.com 获取请求baidu.com的请求头
参考资料
wget
下载网络上一个文件,基本上就是有个命令行版的下载工具了。
基本用法
wget xindoo.me/test.txt 把我服务器上test.txt文件下载到本地
其他
yum|apt install
很多时候服务器上没有我们想要的工具,可以用这个命令安装下,yum是Fedora和RedHat以及CentOS中的Shell前端软件包管理器, apt是ubuntu平台上的。
基本用法
yum install curl
apt install curl
man
这个命令是用来查看其它命令手册的,可以看到具体某个命令的详细作用,和具体参数。这个是个很重要的命令了,一般他会比各命令自带的--help详细很多。
基本用法
man curl 查看curl命令的手册


![[翻译]虚拟内存介绍-XINDOO](https://img-blog.csdnimg.cn/20200625144157603.png)